문제
하드디스크는 한 번에 하나의 작업만 수행할 수 있습니다. 디스크 컨트롤러를 구현하는 방법은 여러 가지가 있습니다. 이 문제에서는 우선순위 디스크 컨트롤러라는 가상의 장치를 이용한다고 가정합니다. 우선순위 디스크 컨트롤러는 다음과 같이 동작합니다.
- 어떤 작업 요청이 들어왔을 때 작업의 번호, 작업의 요청 시각, 작업의 소요 시간을 저장해 두는 대기 큐가 있습니다. 처음에 이 큐는 비어있습니다.
- 디스크 컨트롤러는 하드디스크가 작업을 하고 있지 않고 대기 큐가 비어있지 않다면 가장 우선순위가 높은 작업을 대기 큐에서 꺼내서 하드디스크에 그 작업을 시킵니다. 이때, 작업의 소요시간이 짧은 것, 작업의 요청 시각이 빠른 것, 작업의 번호가 작은 것 순으로 우선순위가 높습니다.
- 하드디스크는 작업을 한 번 시작하면 작업을 마칠 때까지 그 작업만 수행합니다.
- 하드디스크가 어떤 작업을 마치는 시점과 다른 작업 요청이 들어오는 시점이 겹친다면 하드디스크가 작업을 마치자마자 디스크 컨트롤러는 요청이 들어온 작업을 대기 큐에 저장한 뒤 우선순위가 높은 작업을 대기 큐에서 꺼내서 하드디스크에 그 작업을 시킵니다. 또, 하드디스크가 어떤 작업을 마치는 시점에 다른 작업이 들어오지 않더라도 그 작업을 마치자마자 또 다른 작업을 시작할 수 있습니다. 이 과정에서 걸리는 시간은 없다고 가정합니다.
예를 들어
- 0ms 시점에 3ms가 소요되는 0번 작업 요청
- 1ms 시점에 9ms가 소요되는 1번 작업 요청
- 3ms 시점에 5ms가 소요되는 2번 작업 요청
와 같은 요청이 들어왔습니다. 이를 그림으로 표현하면 다음과 같습니다.
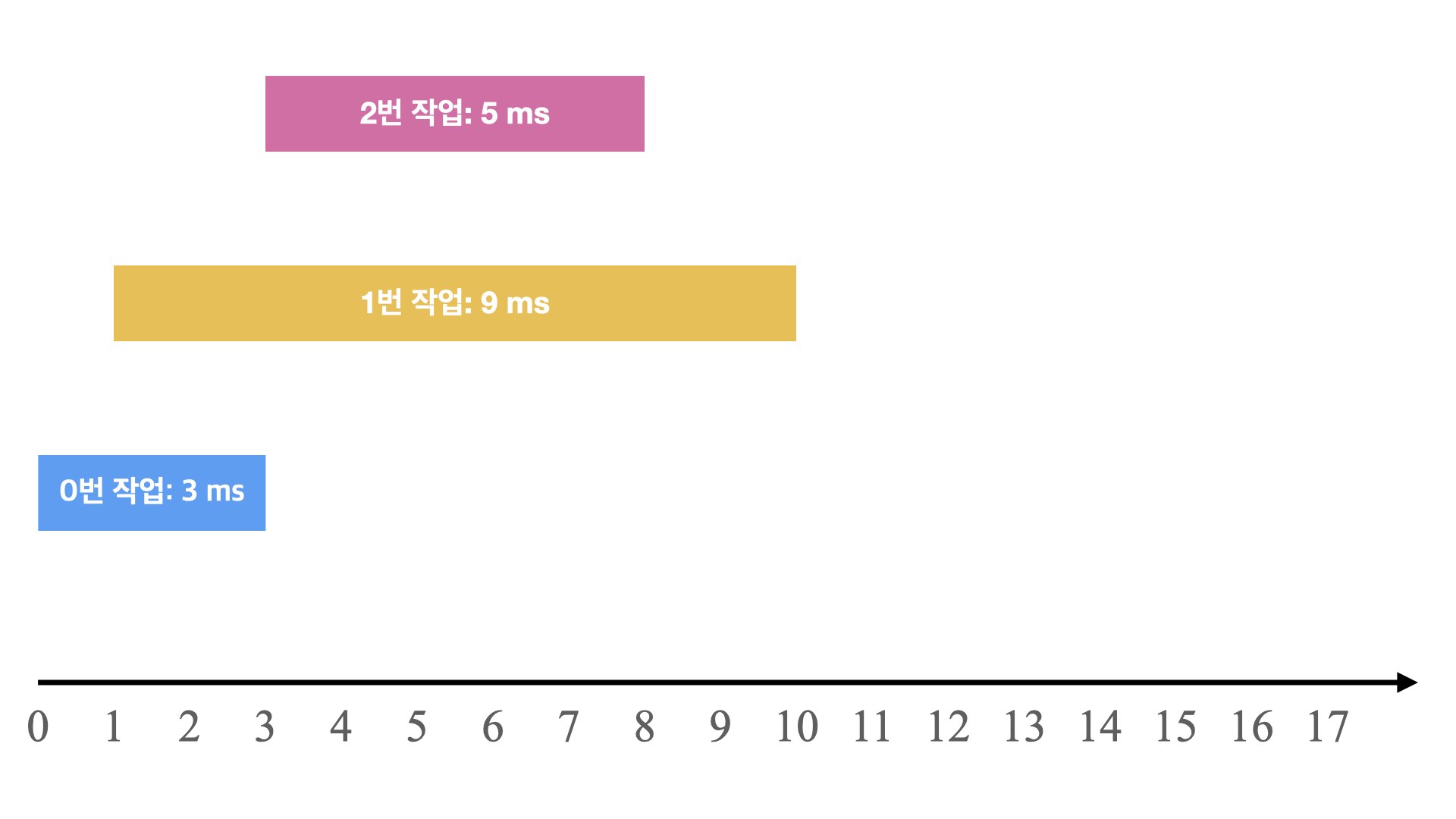
이 요청을 우선순위 디스크 컨트롤러가 처리하는 과정은 다음 표와 같습니다.
| 시점 | 하드디스크 | 대기 큐 | 디스크 컨트롤러 |
|---|---|---|---|
| 0ms | [] | ||
| 0ms | 0번, 0ms, 3ms | 0번 작업 요청을 대기 큐에 저장 | |
| 0ms | 0번 작업 시작 | [] | 대기 큐에서 우선순위가 높은 0번 작업을 꺼내서 작업을 시킴 |
| 1ms | 0번 작업 중 | 1번, 1ms, 9ms | 1번 작업 요청을 대기 큐에 저장 |
| 3ms | 0번 작업 완료 | 1번, 1ms, 9ms | |
| 3ms | [[1번, 1ms, 9ms], [2번, 3ms, 5ms]] | 2번 작업 요청을 대기 큐에 저장 | |
| 3ms | 2번 작업 시작 | 1번, 1ms, 9ms | 대기 큐에서 우선순위가 높은 2번 작업을 꺼내서 작업을 시킴 |
| 8ms | 2번 작업 완료 | 1번, 1ms, 9ms | |
| 8ms | 1번 작업 시작 | [] | 대기 큐에서 우선순위가 높은 1번 작업을 꺼내서 작업을 시킴 |
| 17ms | 1번 작업 완료 | [] |
모든 요청 작업을 마쳤을 때 각 작업에 대한 **반환 시간(turnaround time)**은 작업 요청부터 종료까지 걸린 시간으로 정의합니다. 위의 우선순위 디스크 컨트롤러가 처리한 각 작업의 반환 시간은 다음 그림, 표와 같습니다.
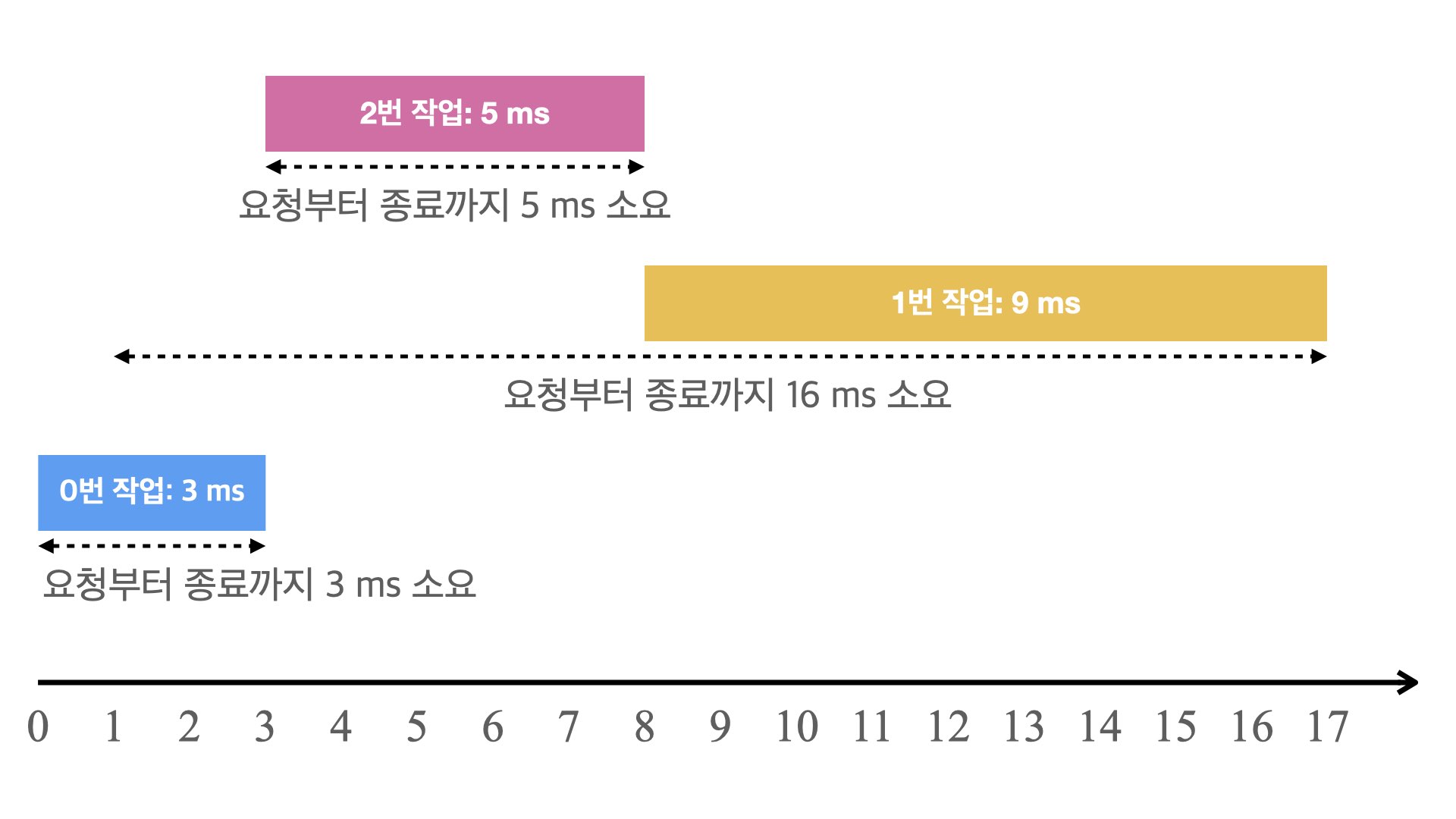
| 작업 번호 | 요청 시각 | 작업 종료 시각 | 반환 시간 |
|---|---|---|---|
| 0번 | 0ms | 3ms | 3ms(= 3ms - 0ms) |
| 1번 | 1ms | 17ms | 16ms(= 17ms - 1ms) |
| 2번 | 3ms | 8ms | 5ms(= 8ms - 3ms) |
우선순위 디스크 컨트롤러에서 모든 요청 작업의 반환 시간의 평균은 8ms(= (3ms + 16ms + 5ms) / 3)가 됩니다.
각 작업에 대해 [작업이 요청되는 시점, 작업의 소요시간]을 담은 2차원 정수 배열 jobs가 매개변수로 주어질 때, 우선순위 디스크 컨트롤러가 이 작업을 처리했을 때 모든 요청 작업의 반환 시간의 평균의 정수부분을 return 하는 solution 함수를 작성해 주세요.
제한 사항
- 1 ≤
jobs의 길이 ≤ 500 jobs[i]는i번 작업에 대한 정보이고 [s, l] 형태입니다.- s는 작업이 요청되는 시점이며 0 ≤ s ≤ 1,000입니다.
- l은 작업의 소요시간이며 1 ≤ l ≤ 1,000입니다.
입출력 예
| jobs | return |
|---|---|
| [[0, 3], [1, 9], [3, 5]] | 8 |
입출력 예 설명
입출력 예 #1
- 문제에 주어진 예와 같습니다.
풀이
처음 제출했던 코드 (30.0/100.0)
#include <string>
#include <vector>
#include <queue>
#include <algorithm>
using namespace std;
struct Job {
int idx, request_time, duration_time;
Job(int idx, int request_time, int duration_time)
: idx(idx), request_time(request_time), duration_time(duration_time) {}
};
struct cmp {
bool operator() (Job a, Job b) {
if (a.duration_time != b.duration_time) {
return a.duration_time > b.duration_time; // 소요시간 크면 순위 낮아진다
}
if (a.request_time != b.request_time) {
return a.request_time > b.request_time; // 요청시간 크면 순위 낮아진다
}
if (a.idx != b.idx) {
return a.idx > b.idx; // 인덱스 번호 크면 순위 낮아진다
}
}
};
int solution(vector<vector<int>> jobs) {
int answer = 0;
// 대기 큐에서 꺼내는 우선 순위 1. 소요시간 짧은 것 2. 요청시각 빠른 것 3. 작업 번호 작은 것
// 반환 시간 = 작업 종료 시각 - 요청 시각
// 구할 것: 모든 요청 작업의 반환 시간의 평균의 "정수 부분"
// 적용할 알고리즘 우선순위 큐
int clock = 0; // 현재 시각 표시
priority_queue<Job, vector<Job>, cmp> pq;
// 요청시간 기준으로 저장
vector<Job> sort_jobs;
for (int i=0; i<jobs.size(); i++) {
int cur_idx = i;
int cur_request_time = jobs[i][0];
int cur_duration_time = jobs[i][1];
sort_jobs.push_back(Job(cur_idx, cur_request_time, cur_duration_time));
}
sort(sort_jobs.begin(), sort_jobs.end(), [](Job a, Job b) {
return a.request_time < b.request_time; // 요청시간에 따라 오름차순 정렬
});
int p = 0; // 대기큐에 들어가지 않은 작업들을 관리하는 포인터
while (p < sort_jobs.size() || !pq.empty()) { // 남은 작업들이 없으며, 대기큐가 비어있으면 종료
// 해당 시점 이전에 요청된 작업들을 대기큐에 삽입
while (p < sort_jobs.size() && sort_jobs[p].request_time <= clock) {
pq.push(sort_jobs[p]);
p++;
}
// 우선순위 높은 것을 대기큐에서 꺼내서 작업
Job cur_job = pq.top();
pq.pop();
clock += cur_job.duration_time;
answer += clock - cur_job.request_time;
}
answer /= sort_jobs.size();
return answer;
}작업이 끝났는데, 대기큐에 아무런 작업도 없는 상황이라면
pq.top()으로 아무 작업도 꺼내올 수 없으므로 에러가 발생한다. 따라서pq.top()으로 꺼내오기 전에 대기큐가 비어있는지 확인 후, 비어있다면 포인터가 가리키는 원소로 clock을 업데이트한다.
정답 풀이
#include <string>
#include <vector>
#include <queue>
#include <algorithm>
using namespace std;
struct Job {
int idx, request_time, duration_time;
Job(int idx, int request_time, int duration_time)
: idx(idx), request_time(request_time), duration_time(duration_time) {}
};
struct cmp {
bool operator() (Job a, Job b) {
if (a.duration_time != b.duration_time) {
return a.duration_time > b.duration_time; // 소요시간 크면 순위 낮아진다
}
if (a.request_time != b.request_time) {
return a.request_time > b.request_time; // 요청시간 크면 순위 낮아진다
}
if (a.idx != b.idx) {
return a.idx > b.idx; // 인덱스 번호 크면 순위 낮아진다
}
}
};
int solution(vector<vector<int>> jobs) {
int answer = 0;
// 대기 큐에서 꺼내는 우선 순위 1. 소요시간 짧은 것 2. 요청시각 빠른 것 3. 작업 번호 작은 것
// 반환 시간 = 작업 종료 시각 - 요청 시각
// 구할 것: 모든 요청 작업의 반환 시간의 평균의 "정수 부분"
// 적용할 알고리즘 우선순위 큐
int clock = 0; // 현재 시각 표시
priority_queue<Job, vector<Job>, cmp> pq;
// 요청시간 기준으로 저장
vector<Job> sort_jobs;
for (int i=0; i<jobs.size(); i++) {
int cur_idx = i;
int cur_request_time = jobs[i][0];
int cur_duration_time = jobs[i][1];
sort_jobs.push_back(Job(cur_idx, cur_request_time, cur_duration_time));
}
sort(sort_jobs.begin(), sort_jobs.end(), [](Job a, Job b) {
return a.request_time < b.request_time; // 요청시간에 따라 오름차순 정렬
});
int p = 0; // 대기큐에 들어가지 않은 작업들을 관리하는 포인터
while (p < sort_jobs.size() || !pq.empty()) { // 남은 작업들이 없으며, 대기큐가 비어있으면 종료
// 해당 시점 이전에 요청된 작업들을 대기큐에 삽입
while (p < sort_jobs.size() && sort_jobs[p].request_time <= clock) {
pq.push(sort_jobs[p]);
p++;
}
if (pq.empty()) {
clock = sort_jobs[p].request_time;
continue;
}
// 우선순위 높은 것을 대기큐에서 꺼내서 작업
Job cur_job = pq.top();
pq.pop();
clock += cur_job.duration_time;
answer += clock - cur_job.request_time;
}
answer /= sort_jobs.size();
return answer;
}